Speaker Gender and Identity Processing
Description
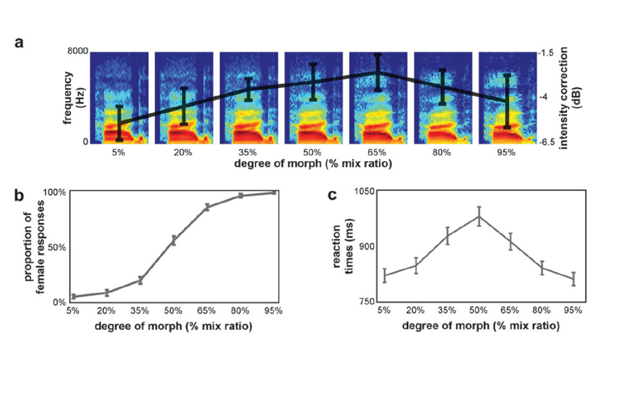
Experiments use voice morphing to generate sound continua between gens. Perceptual ders (link to Downloads#gender) or identities (link to Downloads#identity) allowing precise control of acoustical differences and that are used in behavioural and neuroimaging experiments.
The discrimination of unfamiliar speakers appears to obey the voice space metaphor, inspired from the face recognition literature: each voice can be viewed as a point in a multidimensional space with dimensions corresponding to auditory features used to discriminate speakers; voices close to one another in that space are hard to discriminate from one another, while voices far apart are easily discriminable (Baumann & Belin, 2010; Latinus et al, 2011, 2013). Using multidimensional scaling analyses of identity discrimination performance for many speaker pairs (Baumann & Belin, 2010) we have shown that the two main dimensions of the voice space in human listeners are f0 (fundamental frequency, reflecting the rate of vocal fold oscillation) and formant dispersion (average frequency difference between formant, or vocal tract resonances, reflecting vocal tract size) ; harmonic-to-noise ratio (HNR), reflecting voice irregularities provides a third important dimension(Latinus et al, 2013). Notably, voice perception in that space follows norm-based coding: voices closer in voice space to a voice prototype (well approximated by the morphing-generated average of many speakers of the same gender) are perceived as less distinctive than voices less acoustically similar (farther away in voice space) to the prototype (Latinus et al, 2013). Human listeners are particularly accurate at voice gender recognition, using a combination of f0 and formant cues (Pernet & Belin, 2012)—reflecting the fact that both source and filter aspects of human voice production are strongly sexually dimorphic. Indeed norm-based coding is based on two male and female voice prototypes (Latinus et al, 2013 ).
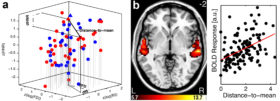 Figure – Norm-based coding of voice identity in the human TVAs. a. Voices as points in a 3D “Voice space” with dimensions reflecting: f0, formant dispersion, harmonics-to-noise ratio. b. The Euclidian distance between a voice and its same-gender prototype (“distance-to-mean”) is a strong predictor of the voice’s evoked neural activity in right TVAm (Latinus et al, 2013).
Figure – Norm-based coding of voice identity in the human TVAs. a. Voices as points in a 3D “Voice space” with dimensions reflecting: f0, formant dispersion, harmonics-to-noise ratio. b. The Euclidian distance between a voice and its same-gender prototype (“distance-to-mean”) is a strong predictor of the voice’s evoked neural activity in right TVAm (Latinus et al, 2013).
The cerebral processing of speaker identity involves both temporal lobe and prefrontal regions with strong right-hemispheric lateralization. The most anterior voice-sensitive region of the right temporal lobe (right TVAa) shows adaptation to speaker identity, i.e., smaller response to syllables spoken by a single speaker than to syllables spoken by multiple speakers (Belin & Zatorre, 2003) and is more active when listeners focus attention on speaker identity as opposed to sentence meaning (von Kriegstein et al, 2004). Studies using multi-voxel pattern analysis (MVPA) beautifully confirm this dissociation: whereas voxels most informative for classifying vowels are distributed bilaterally, those most informative for classifying speaker identity are mostly distributed along right STG/STS particularly its more anterior part (Formisano et al, 2008).
Unfamiliar voices are coded in the TVAs using norm-based coding, confirming behavioural evidence: voices acoustically close to their (own-gender) prototype elicit smaller TVA activity than more distinctive, acoustically dissimilar voices (Figure) (Latinus et al, 2013). (Note that short-term adaptation has been ruled out as an explanation for this result but that the role of long-term experience remains unclear in shaping the voice prototypes.) Inferior prefrontal regions are involved in the learning of new voice identities (Latinus et al, 2011; Zäske et al, 2017), also with strong right-hemispheric lateralization, and use norm-based coding for representing familiar identities.
Funding


Collaborators
Dr Marianne Latinus, Dr Ian Charest, Dr Cyril Pernet, Dr Romi Zäske, links to Virginia Aglieri