Download
The Glasgow Voice Memory Test
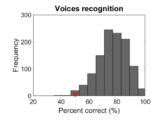 The Glasgow Voice Memory Test (GVMT) is a validated, brief test of voice identity recognition. It lasts around 5 minutes, and includes a non-voice control test using bell sounds. Importantly, the GVMT is language-independent due to the minimal linguistic content of the stimuli (vowel /a/), for easy use across different countries (but Instructions in English). See Aglieri et al (2016) Behavior Research Methods for more information on the GVMT.
The Glasgow Voice Memory Test (GVMT) is a validated, brief test of voice identity recognition. It lasts around 5 minutes, and includes a non-voice control test using bell sounds. Importantly, the GVMT is language-independent due to the minimal linguistic content of the stimuli (vowel /a/), for easy use across different countries (but Instructions in English). See Aglieri et al (2016) Behavior Research Methods for more information on the GVMT.
Take the online Glasgow Voice Memory Test here
Please contact the investigator at pascal.belin@univ-amu.fr to obtain detailed results (please note the time of testing for each participant).
Voice Localizer
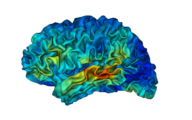 The file TVA_loc.zip contains a set of stimuli to perform in a functional localizer of the temporal voice areas (TVA) with fMRI. This functional localizer lasts 10 minutes and is based on the contrast of vocal vs. nonvocal sounds.
The file TVA_loc.zip contains a set of stimuli to perform in a functional localizer of the temporal voice areas (TVA) with fMRI. This functional localizer lasts 10 minutes and is based on the contrast of vocal vs. nonvocal sounds.
The voice localizer contains 40 8-sec blocs of sounds (16 bit, mono, 22050 Hz sampling rate): 20 blocs (vocal_01 -> vocal_20) consist of only vocal sound (speech as well as nonspeech), and 20 consist of only nonvocal sounds (industrial sounds, environmental sounds, as well as some animal vocalizations). All sounds have been normalized for RMS; a 1kHz tone of similar energy is provided for calibration.
The file TVA_loc.txt provides a proposed order of the sound blocs, optimized for the contrast Vocal vs. Nonvocal. Number 1->20 refer to the 20 vocal blocs; number 21->40 refer to the 20 nonvocal blocs; 99 refers to an 8-sec silence bloc.
The localizer has been planned for a TR of 10 sec (sparse sampling), with a dummy scan at the beginning (starting the sound stimulation), and a beginning of each block 2 sec after beginning of image acquisition. In this case, and following the bloc order suggested in TVA_loc.txt, 61 volumes should be acquired, and the vector of onsets for the two conditions VOCAL and NONVOCAL are (in seconds):
VOCAL = [22 62 82 112 132 162 202 222 242 262 312 352 372 402 432 462 482 512 542 572];
NONVOCAL= [12 32 52 102 122 142 182 232 282 302 322 342 382 422 442 472 502 522 552 592];
Note: it is also possible to use the localizer with a TR of 2 sec, with a continuous scanning noise as background.
See Belin et al (2000) Nature; Pernet et al (2015) Neuroimage
Download the Voice Localizer here
The Montreal Affective Voices
 The MAV consist of 90 nonverbal affect bursts corresponding to emotions of anger, disgust, fear, pain, sadness, surprise, happiness and pleasure (plus a neutral expression) recorded in ten different actors (five male and five females). Ratings of Valence, Arousal and Intensity along eight emotions were collected for each vocalization in thirty participants. Analyses reveal high recognition accuracies for most emotional categories (mean 68%). They also reveal significant effects of both actor’s and participant’s gender: the highest hit rates (75%) were obtained for female participants rating female vocalizations, and the lowest hit rates (60%) for male participants rating male vocalizations. Interestingly, the “mixed” situations, i.e., male participants rating female vocalizations or female participants rating male vocalizations, yielded similar, intermediate ratings. See Belin et al (2008) Behavioral Research Methods
The MAV consist of 90 nonverbal affect bursts corresponding to emotions of anger, disgust, fear, pain, sadness, surprise, happiness and pleasure (plus a neutral expression) recorded in ten different actors (five male and five females). Ratings of Valence, Arousal and Intensity along eight emotions were collected for each vocalization in thirty participants. Analyses reveal high recognition accuracies for most emotional categories (mean 68%). They also reveal significant effects of both actor’s and participant’s gender: the highest hit rates (75%) were obtained for female participants rating female vocalizations, and the lowest hit rates (60%) for male participants rating male vocalizations. Interestingly, the “mixed” situations, i.e., male participants rating female vocalizations or female participants rating male vocalizations, yielded similar, intermediate ratings. See Belin et al (2008) Behavioral Research Methods
Download the Montreal Affective Voices here
The Musical Emotional Bursts
 The MEB have been designed to provide a musical counterpart to the MAVs: short, non-verbal “affect bursts”, here played by professional musicians on a Violin and a Clarinet. MEB stimuli lead to high emotion recognition accuracies and constitute well-matched stimulus sets to compare vocal and musical emotions with minimal linguistic processing. See Paquette, Peretz & Belin (2013) Front Psychol
The MEB have been designed to provide a musical counterpart to the MAVs: short, non-verbal “affect bursts”, here played by professional musicians on a Violin and a Clarinet. MEB stimuli lead to high emotion recognition accuracies and constitute well-matched stimulus sets to compare vocal and musical emotions with minimal linguistic processing. See Paquette, Peretz & Belin (2013) Front Psychol
Download the Musical Affect Bursts here
Voice Averages
Morphing-generated averages of 32 male and 32 female Scottish speakers uttering the word “Hello”. See McAleer et al (2014) PLoS One, Latinus et al (2013) Curr Biol
Download Male voice average here
Download Female voice average here
Voice Gender Continua
 Example synthetic vocalizations generated by morphing between male and female voices, either between natural recordings (Ex1), or between gender-specific averages (Ex2-4). See Pernet & Belin (2012) Front Psychol , Charest et al (2013) Cerebral Cortex
Example synthetic vocalizations generated by morphing between male and female voices, either between natural recordings (Ex1), or between gender-specific averages (Ex2-4). See Pernet & Belin (2012) Front Psychol , Charest et al (2013) Cerebral Cortex
Ex1: natural gender continuum. Download here
Ex2: average gender continuum. Download here
Ex3: same-pitch gender continuum. Download here
Ex4: same-timbre gender continuum. Download here
Voice Emotion Continua
Nonspeech Vocal Emotion continua generated by morphing between exemplars of the Montreal Affective Voices
Continuum Anger to Fear
Voice Discrimination Test
Software used for testing voice discrimination ability in subjects in the upcoming Didic et al, Cortex (in press) article

















